Capítulo 01 - A Web¶
Para o completo funcionamento de uma aplicação Web, que não deixa de ser um site, existe a interação de diversos elementos. Alguns desses elementos são conhecidos por todos, como o navegador (também conhecido como browser ou web browser), outros ficam mais escondidos, como o servidor. Estes dois elementos já formam um modelo mínimo, baseado no modelo cliente-servidor, onde o navegador tem o papel de cliente, acessando o servidor.

Explicando este modelo de forma mais detalhada, o código da aplicação Web fica no servidor, que quando requisitado pelo cliente, neste caso o navegador, permite o acesso a aplicação a este cliente. Vale observar que o navegador e o servidor são dois programas diferentes, podendo estar no mesmo computador em alguns casos, mas na internet o mais comum são computadores diferentes, comunicando via rede, podendo ter sistemas operacionais e até arquiteturas completamente diferentes. Essa diversidade é possível devido a Web seguir padrões, e qualquer programa que implemente estes padrões podem ser utilizados.
Servidor¶
Um servidor é um programa que fica escutando numa porta específica, quando um cliente se conecta e faz alguma requisição, a mesma é processada e uma resposta é devolvida ao cliente. Uma forma fácil de se entender este processo é imaginar arquivos. Num servidor imaginário existem dois arquivos a.png e b.png, quando o cliente conecta e requisita a.png, o servidor pega este arquivo e o envia via rede ao cliente, o mesmo ocorre com b.png.
Existem uma infinidade de servidores, cada um com características próprias, como exigir menos memória, responder uma maior quantidade de requisições simultaneamente, suporte a diversas tecnologias e assim por diante. Exemplo dos servidores mais conhecidos e utilizados são:
Também é possível ter mais de um servidor no mesmo computador, porém a combinação de IP e porta de escuta tem que ser única para cada servidor.
URL¶
Praticamente tudo na Web pode ser acessada via uma URL. Ela possui vários campos que descrevem a localização de um determinado recurso. Seu formato pode ser descrito como:
protocolo://usuário:senha@servidor:porta/recurso
- Protocolo: normalmente em aplicações Web é
http, ouhttpsquando utilizado criptografia. - Usuário e Senha: podem ser fornecidos diretamente na URL quando uma autenticação se faz necessária para acessar determinado recurso. Esses campos são opcionais.
- Servidor: endereço IP ou nome DNS do servidor em qual o recurso encontra-se disponível.
- Porta: número da porta (TCP ou UDP, de acordo com o protocolo). Esse campo é opcional, caso não seja informado será utilizada a porta padrão do protocolo,
80para HTTP,443para HTTPS e assim por diante. Uma relação completa pode ser vista no arquivo/etc/servicesem sistemas UNIX. - Recurso: endereço do recurso que desejá-se acessar, também pode conter várias barras (
/).
Exemplos de URL válidas:
http://localhost/- Requisição do protocolo HTTP para o nome
localhost, na porta80, sem autenticação, recurso/. https://127.0.0.1/- Requisição do protocolo HTTPS (criptografado) para o endereço IP
127.0.0.1, na porta443. http://localhost:8000/- Requisição na porta
8000. http://localhost:8000/arquivo.html- Requisição do recurso
/arquivo.html. http://guest@localhost:8000/imagem/foto.jpg- Requisição com usuário
guest, recurso/imagem/foto.jpg. http://admin:secreta@localhost:8000/segredo/- Requisição com usuário
admine senhasecreta, recurso/segredo/.
Aviso
Cuidado com usuário e senha nas URL!
Qualquer pessoa que conseguir visualizar a URL terá acesso aos mesmos. Muitas vezes é preferível não colocá-las e digitar quando o acesso for feito, ou colocar apenas o usuário, pedindo apenas a senha para acessar.
A URL também pode ser utilizada para indicar onde encontra-se um serviço, como a baixo que indica as informações para acesso a um banco de dados PostgreSQL:
postgres://siteweb:senhamuitosecreta@db.sistema.com.br:5432/bancodedados
Alguns parâmetros opcionais também podem ser passados numa URL, seguindo um formato chave-valor. Para isto basta colocar o símbolo de interrogação (?) no final, seguindo do nome do parâmetro, símbolo de igual (=) e seu valor. Mais de um parâmetro pode ser informado utilizando o e comercial (&). Exemplos:
http://localhost/?pagina=home
http://localhost/login.html?username=admin&password=secreta
Nota
Qualquer caractere diferente de uma letra, número, traço (-) ou underscore (_) em algum campo da URL deve ser codificado!
Isso se faz necessário para não criar confução entre o valor de um campo com o formato da URL em sí. Normalmente se utiliza o símbolo de porcentagem seguido da representação em hexadecimal do caracter em unicode. Exemplo: %20 é um espaço em branco e %21 é uma exclamação (!).
Isto é mais utilizado em nome de arquivos, usuário, senha e parâmetros opcionais, nos demais campos é preferível evitar a utilização de caracteres especiais.
Um caso especial é o símbolo +, que também significa um espaço em branco, da mesma forma que o %20, e não o símbolo propriamente dito.
Nota
Toda vez que for acessar um servidor que está executando no próprio computador, pode ser utilizado os endereços 127.0.0.1 ou localhost, porém eles são nomes diferentes, tanque que o navegador guardará informações diferentes para cada um, além do servidor também poder tratar os acessos de forma diferente.
Caso queira utilizar algum outro nome, porém sem configurá-lo no servidor DNS, o mesmo pode ser feito no arquivo /etc/hosts em sistemas UNIX.
Protocolo HTTP¶
Conforme comentado anteriormente, para permitir que esses diferentes programas se comuniquem existe um padrão. Este padrão é chamado de protocolo HTTP, que descreve o formato das requisições enviadas pelos clientes, e das respostas enviadas pelos servidores.
Programas que enviam requisições, segundo o protocolo HTTP, também são chamados de clientes HTTP. Da mesma forma, os programas que responde as requisições, segundo o protocolo HTTP, também são chamados de servidor HTTP.
Como o protocolo HTTP é um protocolo de rede, ele se baseia em vários outros protocolos para o seu funcionamento, sendo os mais importantes:
- IP: atribui um endereço a cada dispositivo conectado na rede, permitindo a identificação para qual equipamento uma requisição deve ser enviada, ou de qual equipamento originou-a e aguarda resposta.
- DNS: atribui nomes mais fáceis de lembrar aos endereços numéricos do IP.
- TCP: define um processo para a comunicação entre programas diferentes, garantindo que a integridade das informações enviadas baseado em verificações.
- TLS/SSL: permite a criptografia da comunicação do protocolo HTTP, que quando utilizado também é conhecido por HTTPS.
O primeiro passo para ter uma aplicação Web publicada é configurar um servidor HTTP, o processo consiste em escutar uma porta TCP, que por padrão é a 80. Depois que o servidor estiver em execução, o cliente poderá se conectar nesta porta, enviando suas requisições.
Requisição HTTP¶
O protocolo HTTP define o padrão que as requisições devem seguir. O padrão é em texto claro, separado em duas sessões principais cabeçalho e corpo. O cabeçalho define principalmente qual recurso que está sendo requisitado, junto com algumas informações do cliente. O corpo é uma parte que nem sempre está presente, que pode conter os dados de um formulário, ou um arquivo enviado ao servidor, por exemplo.
Um exemplo de uma requisição apenas com cabeçalho:
1 2 3 4 5 6 | GET /home.html HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: localhost:8000
User-Agent: HTTPie/0.9.2
|
Um exemplo de uma requisição com cabeçalho e corpo:
1 2 3 4 5 6 7 8 9 10 | POST /login HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Content-Length: 31
Content-Type: application/x-www-form-urlencoded; charset=utf-8
Host: localhost:8000
User-Agent: HTTPie/0.9.2
username=usuario&password=senha
|
No segundo exemplo pode-se notar que a divisão entre o cabeçalho e o corpo é feita com uma linha em branco, esta linha que define o fim do cabeçalho. Em ambos os casos a primeira linha indica o método da requisição (GET e POST), endereço do recurso (/home.html e /login), terminando com a versão do protocolo (HTTP/1.1). Nas demais linhas do cabeçalho existem algumas informações extras no formato de chave-valor, separado por dois pontos (:).
Para o desenvolvimento de uma aplicação não é necessário entender toda uma requisição profundamente, porém as ideias de método, endereço do recurso, cabeçalho e corpo são importantes.
No método existem algumas palavras chaves, sendo as principais GET e POST. Existe uma diferença na semântica dos dois, porém a principal diferença é que uma requisição GET não possui corpo, enquanto uma requisição POST possui.
Endereço de recurso pode ser entendido como o endereço ou caminho de um arquivo, ao se configurar um servidor para servir arquivos de um diretório via HTTP, isso é completamente válido. Porém não é limitado apenas a endereços de arquivos, como explicado mais adiante.
Algumas informações interessantes no cabeçalho destas requisições são:
Host: indica que site foi acessado pelo cliente, bastante importante para quando existem mais de um site disponível no mesmo servidor, ou quando o acesso é feito via proxy.User-Agent: uma assinatura do programa que fez a requisição, aqui pode-se ver que foi utilizado o HTTPie, porém esta informação não é confiável, uma vez que pode ser alterada facilmente.Content-Type(apenas noPOST): formato utilizado no corpo da requisição.
Com relação ao corpo da requisição POST, está codificada no formato application/x-www-form-urlencoded, utilizando utf-8 para a representação dos caracteres, conforme descrito em Content-Type. Este formato é utilizado principalmente para formulários, e tem o seu funcionamento conforme descrito nos parâmetros opcionais da URL.
Resposta HTTP¶
Depois que uma linha em branco demarca o fim do cabeçalho da requisição HTTP, o seu corpo foi recebido pelo servidor se estiver presente na requisição, a mesma será processada e devolvida na forma de uma resposta HTTP. A resposta também se divide em cabeçalho e corpo, assim como a requisição, porém possui algumas diferenças:
1 2 3 4 5 6 7 8 | HTTP/1.0 200 OK
Content-Length: 15
Content-type: text/html
Date: Thu, 24 Dec 2015 01:33:41 GMT
Last-Modified: Thu, 24 Dec 2015 01:33:37 GMT
Server: SimpleHTTP/0.6 Python/3.4.2
<h1>Teste</h1>
|
Na primeira linha tem a versão do protocolo, pode-se notar que este servidor não suporta completamente a versão 1.1, e respondeu conforme a versão 1.0. Logo em seguida tem o código da resposta e o mensagem, neste caso 200 OK. Existem algumas famílias de código de resposta, sendo as mais comuns descritas a baixo:
| Família | Descrição | Exemplo |
|---|---|---|
| 2XX | Requisição recebida e processada corretamente. | 200 OK |
| 3XX | Redirecionamentos, quando o recurso encontra-se em outro lugar. | 301 Moved permanently |
| 4XX | O recurso não pode ser acessado pelo cliente. | 404 File not found |
| 5XX | Erro durante o processamento da requisição no servidor. | 500 Internal server error |
Algumas coisas que pode-se notar neste cabeçalho são:
- Content-Length: indica o tamanho de corpo da resposta, útil em downloads, para se fazer uma previsão do término, quando não informado não é possível determinar quando o mesmo terminará.
- Contnet-Type: indica de qual é o formato do corpo da resposta, funciona da mesma forma que a requisição.
- Date e Last-Modified: indica o horário do servidor quando respondeu e a última modificação do arquivo, pode-se ser utilizado para fazer cache de uma página e não precisar baixá-la novamente caso não tenha sofrido nenhuma modificação.
- Server: uma assinatura do programa que fez a resposta, deve-se tomar cuidado na configuração do servidor em produção para não expor informações de mais que permitam identificar uma falha de segurança, como versões.
Logo em seguida tem o corpo da resposta que é a página propriamente dita.
Fluxo de requisição/resposta¶
Tudo no protocolo HTTP funciona baseado neste fluxo de enviar uma requisição e obter a resposta. Com isso é possível dizer que o HTTP não guarda estado, já que cada requisição é feita separadamente e uma requisição não tem relação direta com outra.
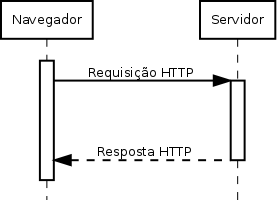
Porém existe uma forma de adicionar identificadores para saber quem é determinado cliente ou se o mesmo fez o login dentro da página. Isso é feito baseado em cookies, que é um campo no cabeçalho. Numa resposta o campo Set-Cookie: nome=valor define um cookie, na próxima requisição essa informação será passada no cabeçalho como Cookie: nome=valor.
Aviso
O valor dos cookies são enviados em texto claro sem criptografia, por este motivo evite guardar informações como senha. Prefira manter essa informação no servidor, passando apenas um código identificador da mesma, como um UUID, porém este código deve ser gerado aleatoriamente para não ser previsivél ou facilmente descoberto por terceiros.
Muitas linguagens ou frameworks implementam um recurso semelhante ao descrito sobre o nome de sessão.
Mimetype¶
Sempre que existe um corpo numa requisição ou resposta, é necessário dizer qual o tipo desta informação, como se fosse um formato. Esses tipos seguem o padrão mimetype, que é composto por duas partes separadas por barra (/), na primeira tem uma categoria e o formato na segunda. Essa informação é importante para que o cliente saiba o que fazer com esta informação, como qual o formato que deverá exibí-la.
Alguns exemplos de mimetypes são:
text/plain
text/html
application/json
image/png
video/webm
Em sistemas UNIX os mimetypes podem ser verificados no arquivo /etc/mime.types ou com o comando mimetype <arquivo>.
Algumas vezes também pose conter alguma informação adicional como text/html; charset=utf-8, que além de dizer que o arquivo é um HTML, já identifica qual o conjunto de caracteres que deve ser utilizado para ler seu conteúdo.
Exercícios¶
- Crie um diretório no seu computador, com o arquivo
index.htmlcom o código a baixo:
- Execute o comando a seguir dentro deste diretório.
python -m http.server
- (Opcional) Faça requisições utilizando o HTTPie, alguns exemplos:
http http://localhost:8000/ -v http http://localhost:8000/index.html -v http http://localhost:8000/naoexiste.html -vNota
É possível instalar o HTTPie com o comando
pip. Exemplo:pip install httpie
- Faça requisições utilizando um navegador gráfico como o Mozilla Firefox:
http://localhost/ http://localhost:8000/ http://127.0.0.1:8000/ http://localhost:8000/index.html
- Execute o comando a baixo e acesse
http://localhost:8080/:
python -m http.server 8080
- (Opcional) Copie uma imagem para este diretório e tente abri-la no navegador.
- (Opcional) Crie subdiretórios com arquivos e tente acessá-los.
- (Opcional) Num diretório com vários arquivos, porém sem um
index.html, execute um servidor HTTP e seja a página que será gerada automaticamente.
Discussão¶
- Quando executado dois servidores ao mesmo tempo aparece o seguinte erro:
Traceback (most recent call last): File "/usr/lib/python3.4/runpy.py", line 170, in _run_module_as_main "__main__", mod_spec) File "/usr/lib/python3.4/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/lib/python3.4/http/server.py", line 1241, in <module> test(HandlerClass=handler_class, port=args.port, bind=args.bind) File "/usr/lib/python3.4/http/server.py", line 1214, in test httpd = ServerClass(server_address, HandlerClass) File "/usr/lib/python3.4/socketserver.py", line 429, in __init__ self.server_bind() File "/usr/lib/python3.4/http/server.py", line 133, in server_bind socketserver.TCPServer.server_bind(self) File "/usr/lib/python3.4/socketserver.py", line 440, in server_bind self.socket.bind(self.server_address) OSError: [Errno 98] Address already in usePor quê isso ocorre? Como é possível executar dois servidores simultaneamente?
Como é possível que um servidor responda com uma página para uma interface de rede, e com outra página para outra interface de rede?
Para que serve o comando
netstate no que ele pode ser útil?
- Quando executado o comando a baixo é possível acessar os arquivos de outro computador.
python -m http.serverPor quê o mesmo não ocorre com o comando a baixo?
python -m http.server --bind 127.0.0.1
- Por quê com um usuário comum não consegue executar o comando a baixo?
python -m http.server 80O que a seguinte mensagem quer dizer?
Traceback (most recent call last): File "/usr/lib/python3.4/runpy.py", line 170, in _run_module_as_main "__main__", mod_spec) File "/usr/lib/python3.4/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/lib/python3.4/http/server.py", line 1241, in <module> test(HandlerClass=handler_class, port=args.port, bind=args.bind) File "/usr/lib/python3.4/http/server.py", line 1214, in test httpd = ServerClass(server_address, HandlerClass) File "/usr/lib/python3.4/socketserver.py", line 429, in __init__ self.server_bind() File "/usr/lib/python3.4/http/server.py", line 133, in server_bind socketserver.TCPServer.server_bind(self) File "/usr/lib/python3.4/socketserver.py", line 440, in server_bind self.socket.bind(self.server_address) PermissionError: [Errno 13] Permission denied